基于Apache Flink 1.6.x
1 Get Started
Flink SQL是Flink高层API,语法遵循ANSI SQL标准。示例如下
1 | SELECT car_id, MAX(speed), COUNT(speed) |
Flink SQL是在Flink Table API的基础上发展起来的,与上述示例对应的Table API示例如下
1 | table.where('speed > 90) |
上述示例使用Scala代码,结合隐式转换和中缀表示等Scala语法,Table API代码看起来非常接近SQL表达。
2 架构原理
老版本的Table API通过类似链式调用的写法,构造一棵Table Operator树,并对各个树节点做代码生成,转化成Flink低层API调用代码,即DataStream/DataSet API。
从2016年开始,开源社区已经有大量SQL-on-Hadoop的成熟解决方案,包括Apache Hive、Apache Impala、Apache Drill等等,都依赖Apache Calcite提供的SQL解析优化能力,Apache Calcite当时已经是一个非常流行的业界标准SQL解析和优化框架。于此同时,随着在实时分析领域中Flink的应用场景增加,对SQL API的呼声渐高,于是社区开始在Apache Calcite的基础上构建新版本的Table API,并增加SQL API支持。
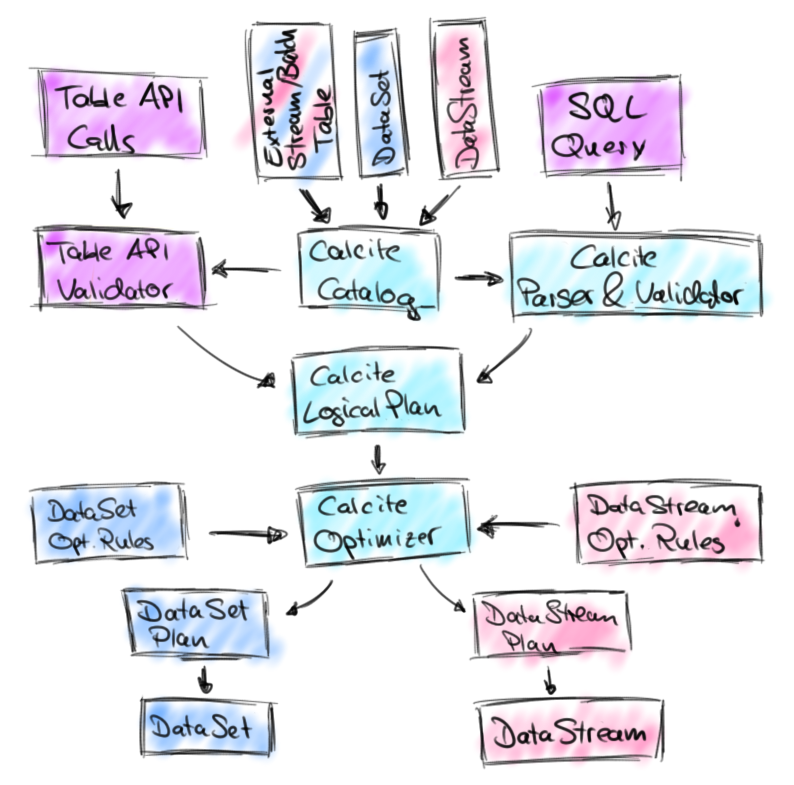
新版本的Table & SQL API在原有的Table API基础上,由Calcite提供SQL解析和优化能力,将Table API调用和SQL查询统一转换成Calcite逻辑执行计划(Calcite RelNode树),并对此进行优化和代码生成,最终同样转化成Flink DataStream/DataSet API调用代码。
3 DDL & DML
完整的SQL语法由DDL(data definition language)和DML(data manipulation language)两部分组成。Flink SQL目前只支持DML语法,而包含数据流定义的DDL语法仍需通过代码实现。
国内各大公有云厂商中,阿里云和华为云提供了基于Flink SQL的实时流计算服务,各自定义了一套DDL语法,语法大同小异。以华为云为例,数据流定义以CREATE STREAM为关键字,具体的DDL写法示例如下
1 | CREATE SOURCE STREAM driver_behavior (car_id STRING, speed INT, collect_time LONG) |
DDL中包含输入数据流和输出数据流定义,描述实时流计算的数据上下游生态组件,在上述例子中,输入流(SOURCE STREAM)类型是Kafka,WITH子句描述了Kafka消费者相关配置。输出流(SINK STREAM)类型是SMN,是华为云消息通知服务的缩写,用于短信和邮件通知。
数据从Kafka流入,向SMN服务流出,而中间的数据处理逻辑由DML实现,具体的DML写法示例如下
1 | INSERT INTO over_speed_warning |
以上DML语句,描述了在30秒内车辆累计超速三次时,向作为输出流的下游SMN组件输出告警消息。DML语句中INSERT INTO关键字后紧接着输出流名,而FROM关键字后紧接着输入流名,SELECT 子句表达输出的内容,WHERE子句表达输出需要满足的过滤条件。上述例子使用到了SQL子查询,外层FROM后跟着一整个SELECT子句,为了方便理解,我们也可以把子查询语法转化成等价的临时流定义表达,在华为云实时流计算服务的DDL语法中支持了这种特性,与上述DML写法等价的示例如下
1 | CREATE TEMP STREAM over_speed_info (car_id STRING, speed INT, overspeed_count INT); |
通过TEMP STREAM 语法定义临时流,可以将带有子查询的SQL语法平铺表达,串接数据流逻辑,更容易理解。
4 语法
Flink SQL的核心部分是DML语法,基础的DML语法包含笛卡尔积(单表情况下只有Scan操作)、选择(Filter)和投影(Projection)三个数据操作部分,三者分别对应FROM子句、WHERE 子句和SELECT子句,这三个部分的顺序代表了DML语句的逻辑执行顺序。较为进阶的语法包含聚合、窗口和连接(JOIN)等常用语法,以及排序、限制和集合等非常用语法。下表简单列举Flink SQL基础和常用的进阶DML语法句式并加以说明,其他语法元素和内建函数等详细内容,可参考Flink SQL文档
- 基础语法
| 操作 | 样例 |
|---|---|
| Scan / Filter / Projection | SELECT car_id, speed FROM drive_data WHERE speed > 90 |
| Scan / FIlter / Projection / Insert | INSERT INTO overspeed SELECT id , speed FROM drive_data WHERE speed > 90 |
- 聚合语法
| 操作 | 样例 | 备注 |
|---|---|---|
| GroupBy Aggregation | SELECT MAX(speed) FROM drive_data GROUP BY car_id | |
| GroupBy Window Aggregation | SELECT car_id, MAX(speed) FROM drive_data GROUP BY TUMBLE(proctime, INTERVAL '1' MINUTE), car_id | GroupBy窗口每个聚合周期输出一批聚合结果 |
| Over Window Aggregation | SELECT MAX(speed) OVER ( PARTITION BY car_id ORDER BY proctime RANGE BETWEEN INTERVAL '30' SECOND PRECEDING AND CURRENT ROW) FROM drive_data | Over窗口每进入一条数据就输出一条聚合结果,且所有的投影属性的Over窗口必须一致 |
- 连接语法
| 操作 | 样例 | 备注 |
|---|---|---|
| Inner Euiq-join | SELECT * FROM drive_data INNER JOIN car_info ON drive_data.car_id = car_info.id | 当前只支持等值连接 |
| Time-windowed Join | SELECT * FROM drive_data d, camera_data c WHERE d.car_id = c.car_id AND d.proctime BETWEEN c.proctime - INTERVAL '30' SECOND AND c.proctime | |
| Table Join | SELECT * FROM drive_data INNER JOIN car_info ON drive_data.car_id = car_info.id | 流表Join语法和流流Join语法类似,Flink SQL目前不支持流表Join,阿里云和华为云实时流计算服务的SQL语法是支持的 |
5 场景
目前Flink SQL的应用场景主要包括ETL实时入库、实时大屏、实时告警等等。
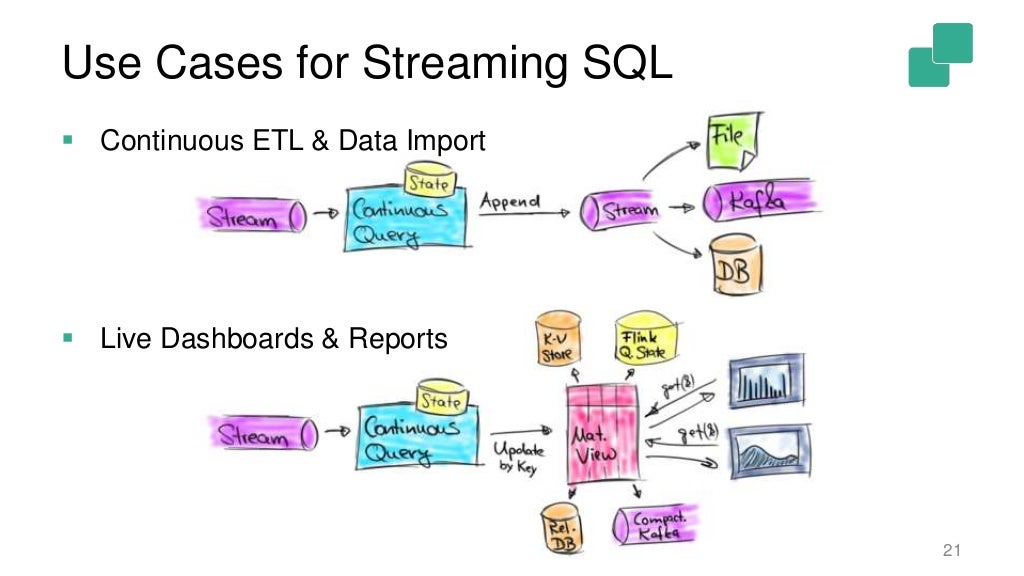
在IoT领域和车联网领域也大量存在潜在的使用场景,华为云实时流计算服务提供了针对这些场景的SQL扩展,包括地理函数,CEP SQL等支持,还支持Streaming ML语法用SQL表达多种实时机器学习算法,包括随机森林算法实现异常检测等场景。